

Когда роботы поисковых систем посещают веб-сайты, они обращаются к файлу robots.txt, который указывает им, что они могут и не могут индексировать на сайте. Это очень полезный инструмент для владельцев сайтов, чтобы контролировать, какая информация доступна для поиска, а какая должна остаться скрытой.
Вопрос настройки robots.txt становится особенно важным, когда речь идет о конфиденциальной информации или ограниченных разделах сайта. Например, если у вас есть раздел сайта, в котором хранятся личные данные пользователей или коммерческие секреты, то вам нужно убедиться, что эта информация не попадет в поисковые результаты.
Также, настройка robots.txt может быть полезна, если у вас есть страницы с низким качеством контента, которые вы не хотите видеть в результатах поиска. Это могут быть страницы с дублирующимся или незначительным контентом, которые могут негативно повлиять на репутацию вашего сайта в глазах поисковых систем.
В этой статье мы рассмотрим, как настроить файл robots.txt и какие разделы сайта стоит скрывать от поисковых роботов. Мы также рассмотрим некоторые лучшие практики по использованию этого файла для оптимизации поисковых запросов и защиты конфиденциальной информации.
Как настроить robots.txt
Чтобы настроить robots.txt, необходимо создать текстовый файл с именем «robots.txt» и разместить его в корневой директории сайта. Затем необходимо указать директивы для разных роботов, например, «User-agent: *» означает, что директивы далее будут применяться ко всем роботам, а «Disallow: /private/» указывает, что путь «/private/» не должен быть индексирован.
В файле robots.txt можно использовать такие директивы, как «Disallow» (запрет индексации определенной страницы или директории), «Allow» (разрешение индексации определенной страницы или директории), «Sitemap» (указание на местоположение файла sitemap.xml), «Crawl-delay» (задержка между запросами роботов) и другие.
Рекомендуется тщательно настраивать robots.txt, чтобы исключить индексацию нежелательных страниц, таких как страницы с личной информацией пользователей, временные страницы, тестовые страницы и другие. Также следует обратить внимание на правильное использование директивы «Disallow» и остерегаться ошибок, которые могут привести к нежелательной блокировке целых секций сайта.
Используя правильно настроенный файл robots.txt, вы можете улучшить процесс индексации вашего сайта поисковыми системами, повысить его SEO-показатели и обеспечить безопасность и конфиденциальность пользователям.
Пример настройки robots.txt
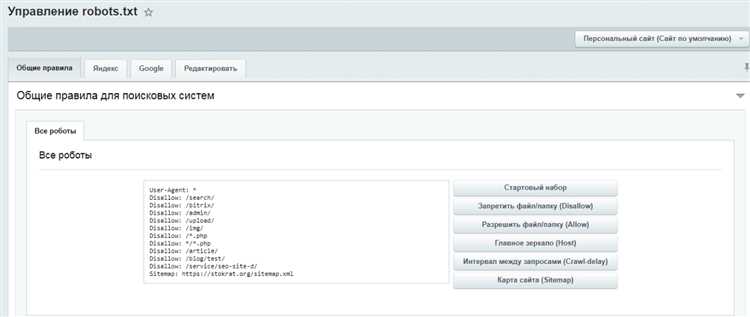
User-agent: * Disallow: /private/ Disallow: /admin/ Allow: /public/ Allow: /css/ Sitemap: https://www.example.com/sitemap.xml Crawl-delay: 10
Зачем нужен файл robots.txt
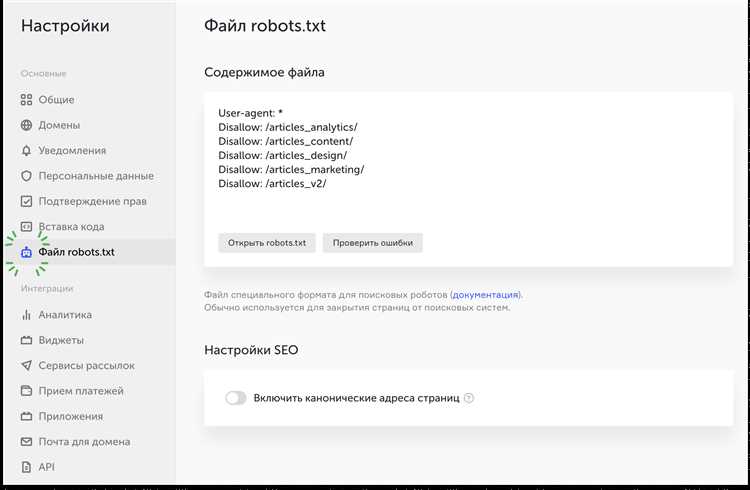
Основная задача файла robots.txt — сообщить роботам, каким образом они должны обращаться с сайтом. Этот файл позволяет задать правила, определяющие, какие страницы разрешено индексировать поисковым системам, а какие страницы исключены из индексации и не должны отображаться в поисковых результатах.
Файл robots.txt помогает веб-мастеру контролировать доступ к конфиденциальным страницам, таким как страницы с личной информацией пользователей, административные страницы или части сайта, которые являются несущественными для поисковых систем.
Кроме того, файл robots.txt позволяет оптимизировать индексацию сайта, исключая страницы, которые не должны появляться в поисковых результатах или добавлять через него схемы разработчиков.
Ограничения для поисковых роботов
Ограничения, установленные в файле robots.txt, позволяют определить, какие страницы сайта необходимо скрыть от индексации или поисковых систем. Это может быть полезно для защиты конфиденциальной информации, такой как личные данные пользователей или другие приватные сведения. Также ограничение доступа к определенным разделам сайта может быть полезно для предотвращения воровства контента или злоупотребления с техническими ресурсами сайта.
Примеры ограничений в robots.txt:
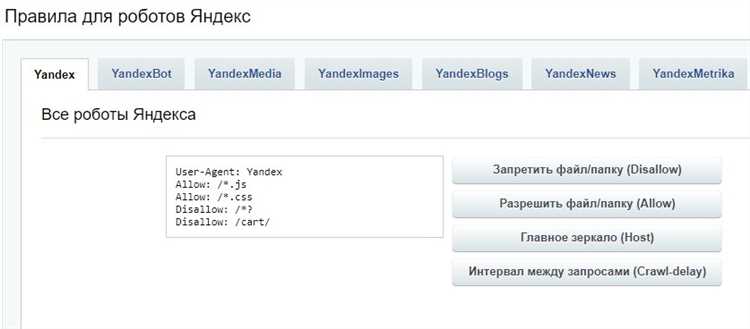
- Запрет индексации всего сайта: User-agent: *
Disallow: / - Запрет индексации определенной папки: User-agent: *
Disallow: /папка/ - Запрет индексации определенного файла: User-agent: *
Disallow: /файл.html
Модификация robots.txt может быть полезной для оптимизации работы поисковых систем и защиты сайта от различных угроз. Однако, следует помнить, что robots.txt не является средством полной защиты информации и может быть проигнорирован некоторыми поисковыми системами или злоумышленниками. Поэтому, для более надежной защиты данных, рекомендуется использовать другие методы, такие как авторизация и шифрование информации.
Запрет на индексацию содержимого
В некоторых случаях сайтовладельцы могут захотеть запретить индексацию содержимого определенных страниц сайта поисковыми системами. Это может быть полезно, например, для страницы «Спасибо за покупку», которую пользователи видят после совершения покупки и которую не имеет смысла индексировать поисковиками.
Для этого в файле robots.txt можно использовать директиву «Disallow». Она указывает поисковым системам, какие страницы должны быть исключены из индексации. При этом следует помнить, что запрет на индексацию содержимого с помощью robots.txt не гарантирует полной защиты, так как некоторые поисковые системы могут проигнорировать эти указания или попытаться проиндексировать страницы в любом случае.
Директива «Disallow» используется вместе с путем к странице или файлу, который не должен быть проиндексирован. Например, чтобы запретить индексацию страницы «Спасибо за покупку», необходимо добавить следующую строку в файл robots.txt:
- User-agent: * (применяется ко всем роботам)
- Disallow: /thank-you.html (запрет на индексацию страницы «Спасибо за покупку»)
Таким образом, поисковые системы будут исключать страницу «Спасибо за покупку» из индекса и не будут ее отображать в результатах поиска.
Однако стоит отметить, что запрет на индексацию содержимого с помощью robots.txt не является абсолютным защитным механизмом. Чтобы полностью исключить индексацию страницы, рекомендуется использовать дополнительные мета-теги в HTML-коде страницы или использовать файлы «noindex». Также следует учитывать, что robots.txt не ограничивает доступ к самой странице, поэтому пользователи все равно могут получить к ней доступ напрямую, если знают ее URL.
Ограничение доступа к конкретным URL-адресам
Для ограничения доступа к определенным URL-адресам вам следует использовать директиву «Disallow» в файле robots.txt. С помощью этой директивы вы указываете роботам запретить индексацию определенных частей вашего сайта. Например, если у вас есть раздел сайта, содержащий личные данные пользователей, вы можете добавить следующую строку в файл robots.txt:
User-agent: *
Disallow: /personal_data/
Таким образом, вы запрещаете всем роботам индексировать любую страницу, находящуюся в папке «personal_data». Это помогает защитить конфиденциальность пользователей и предотвратить возможные утечки информации.
Примечание: Обратите внимание, что директива «Disallow» не является полным запрещением доступа — это лишь рекомендация для роботов поисковых систем. Некоторые роботы могут все равно проиндексировать страницы, указанные в директиве «Disallow». Если вам требуется более строгий контроль доступа, рекомендуется использовать файлы .htaccess или другие методы.
Рекомендации по правильной настройке robots.txt
При правильной настройке robots.txt файл может значительно повысить эффективность индексации вашего сайта поисковыми системами и помочь в управлении трафиком. В данном разделе мы предлагаем вам несколько рекомендаций, которые помогут правильно настроить содержимое robots.txt.
1. Тщательно описывайте разделы сайта
Для того чтобы роботы поисковых систем корректно проиндексировали нужные разделы вашего сайта, обязательно добавьте соответствующие директивы в файл robots.txt. Опишите каждый раздел так, чтобы роботам было понятно, какие страницы можно индексировать, а какие нет.
2. Блокируйте нежелательные разделы
Если на вашем сайте есть разделы, которые не должны попадать в поисковые результаты, добавьте директиву «Disallow» для этих разделов в файле robots.txt. Таким образом, вы сможете скрыть нежелательные страницы от индексации.
3. Используйте дополнительные директивы
Помимо базовых директив «Allow» и «Disallow», в файле robots.txt можно использовать и другие директивы, которые позволят более гибко настроить индексацию. Например, директива «Crawl-delay» позволяет указать задержку между запросами к сайту от поисковых роботов.
4. Проверяйте файл robots.txt на ошибки
После внесения изменений в файл robots.txt рекомендуется проверить его на наличие ошибок. Неправильно настроенный файл может привести к нежелательным последствиям, таким как блокировка доступа к важным разделам сайта для роботов поисковых систем.
Следуя этим рекомендациям, вы сможете настроить robots.txt файл максимально эффективно, управлять индексацией страниц вашего сайта и улучшить его видимость в поисковых системах.